Evaluating multilingual language models
Judit Ács
BME, SZTAKI, ELTE
MILAB-NLU Seminar
February 25, 2021
Introduction
- Contextualized language models have changed the NLP landscape
- Language models that work at the sentence level
- word-level: one vector for a word
- contextualized: one vector for each word in a sentence
- Can assign different vectors to the same word
He is running a marathon.
BERT
- BERT: Transformer-based language model with 100M+ parameters
- Improved the state-of-the-art on many tasks (GLUE, SQuAD, SWAG)
- 6 pretrained checkpoints: 4 English, 2 multilingual (mBERT)
- Many BERT-variants
- difference in the architecture, the training objective or the training data
- Huggingface Transformers library
- PyTorch model classes
- over 1000 pretrained checkpoints
- dataset repository
Evaluating contextualized language models
- Blackbox models, difficult to evaluate
- Extrinsic evaluation: various benchmarks, mainly in English
- Intrinsic evaluation: training metrics
- Diagnostic classifiers or probing is simple and popular
- With or without finetuning?
Agenda
- Overview of the methodology
- Morphological evaluation against various baselines
- Input perturbations, Shapley values
- Choice of subword
- Evaluation for Hungarian
Methodology
Probing
- Also called diagnostic classifiers
- Probing addresses the following questions:
- Does the model encode certain information?
- Can we recover this information?
- Typical steps:
- freeze the model (i.e. no finetuning)
- extract the representation of a word/sentence
- train a small classifier to predict something
- if it performs well, the model 'contains' the information
Types of probing
target of probing: language model, trained NMT modeltype of probing data: word, sentence, sentence pair
probing location: token, token span (edge probing), sentence
probed information: morphology, POS, syntax, semantics
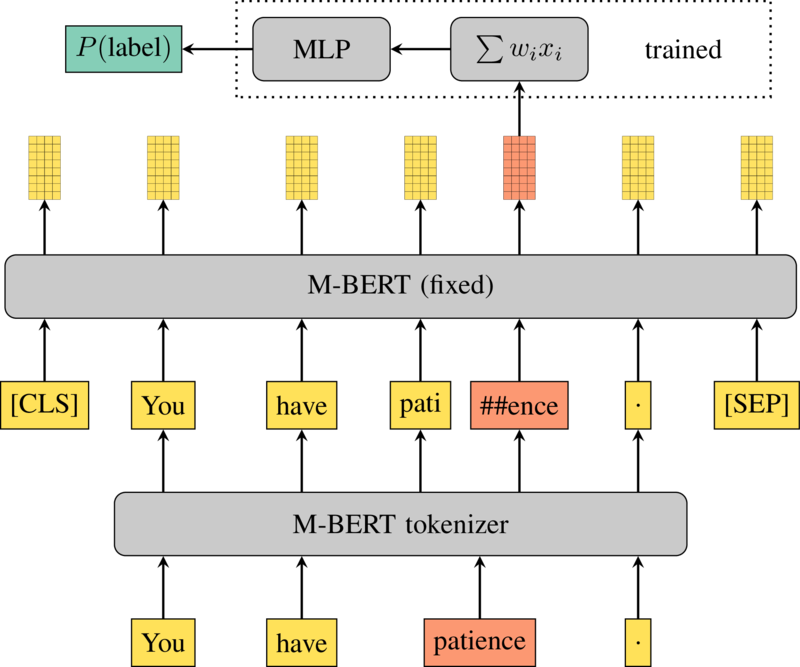
Probing architecture
- Subword tokenization
- Feed it to a language model
- Pick a layer or sum them
- Pick a subword
- Feed its vector to a small MLP
- 1 hidden layer with 50 neurons
- ReLU
- ~40000 trainable parameters
- Compute loss against a label
Morphological evaluation
Morphological probing tasks
- Defined as $\langle$ language, morph tag, part-of-speech $\rangle$
- What tense is cut in in this sentence?
I cut my hair yesterday. Past - Data generated from the Universal Dependencies Treebanks
- Train/dev/test: 2000/200/200
Baselines
- fastText
- WLSTM: character LSTM on the target word
- SLSTM: character LSTM on the full sentence
| contextual | pretrained | tokenization | |
|---|---|---|---|
| M-BERT | yes | yes | wordpiece |
| SLSTM | yes | no | character |
| fastText | no | yes | n-gram |
| WLSTM | no | no | character |
Languages and tasks
- 319 tasks
- 39 languages
- 13 language families
- 4 POS
- 22 tag
Task statistics
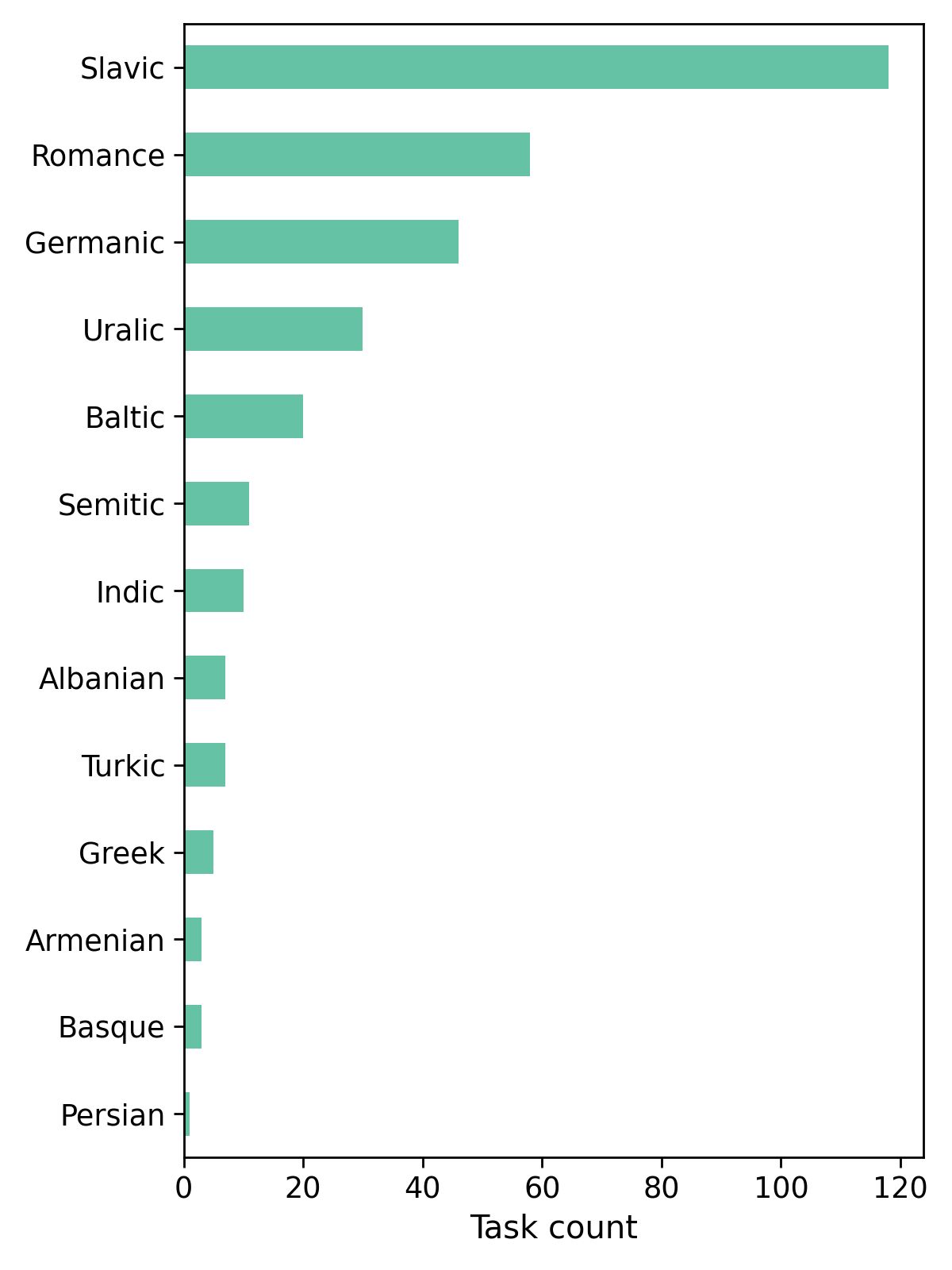
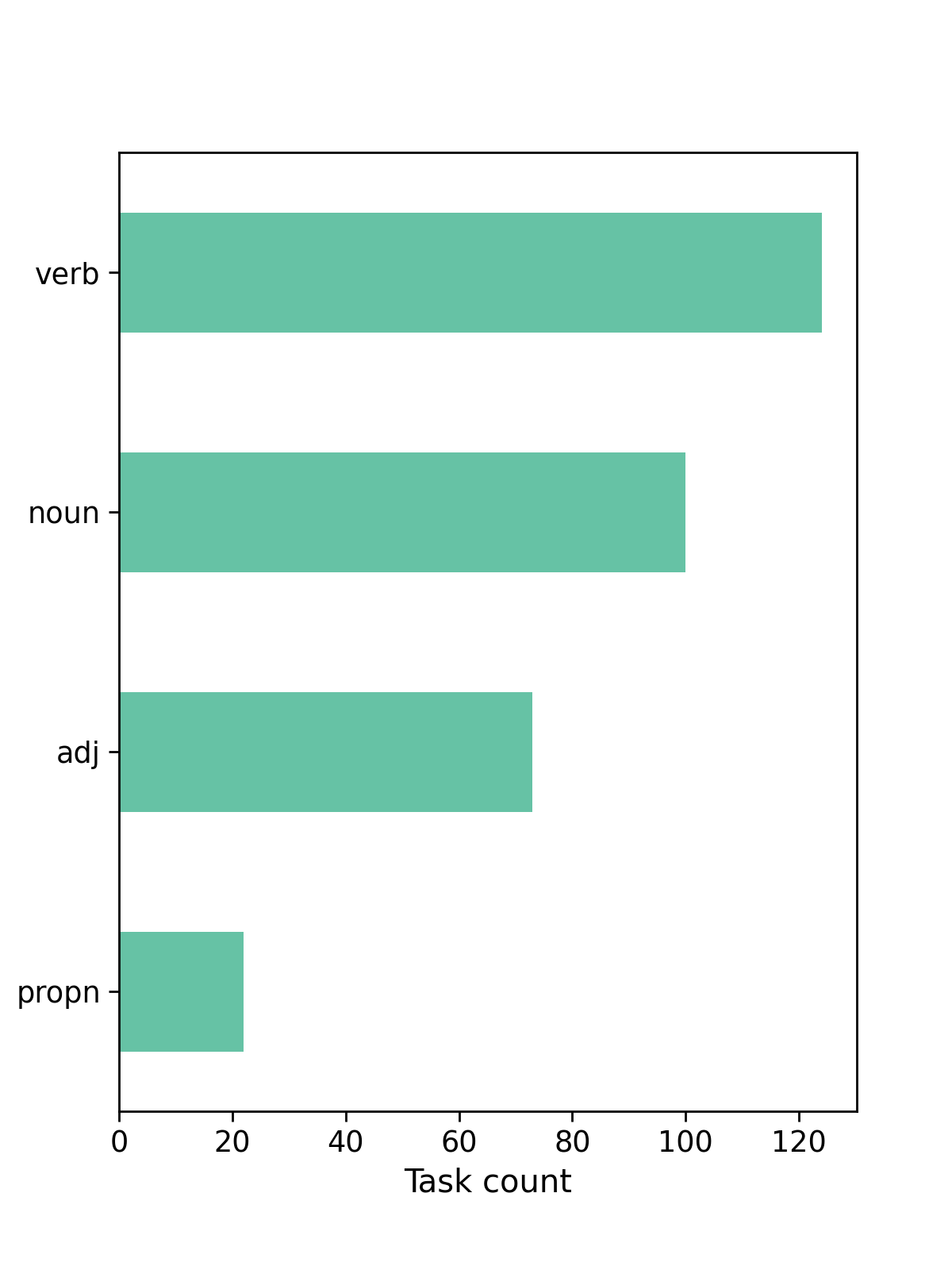
Tasks by language
| Czech | 23 | Croatian | 10 | Norwegian_Bokmal | 7 | Lithuanian | 4 |
| Russian | 20 | Romanian | 10 | Norwegian_Nynorsk | 7 | Urdu | 4 |
| Polish | 19 | Ukrainian | 9 | Turkish | 7 | Portuguese | 4 |
| Finnish | 16 | Slovenian | 8 | Arabic | 6 | Basque | 3 |
| Latvian | 16 | French | 8 | Serbian | 6 | Hungarian | 3 |
| Latin | 13 | Swedish | 8 | Hindi | 6 | English | 3 |
| Slovak | 12 | Catalan | 8 | Hebrew | 5 | Armenian | 3 |
| German | 11 | Italian | 8 | Greek | 5 | Persian | 1 |
| Bulgarian | 11 | Spanish | 7 | Danish | 5 | Afrikaans | 1 |
| Estonian | 11 | Albanian | 7 | Dutch | 4 |
Average accuracy by POS
- Most tasks are 'easy' for both mBERT and the baselines
- Verbal morphology is easier than nominal
- Focus on SLSTM from here on
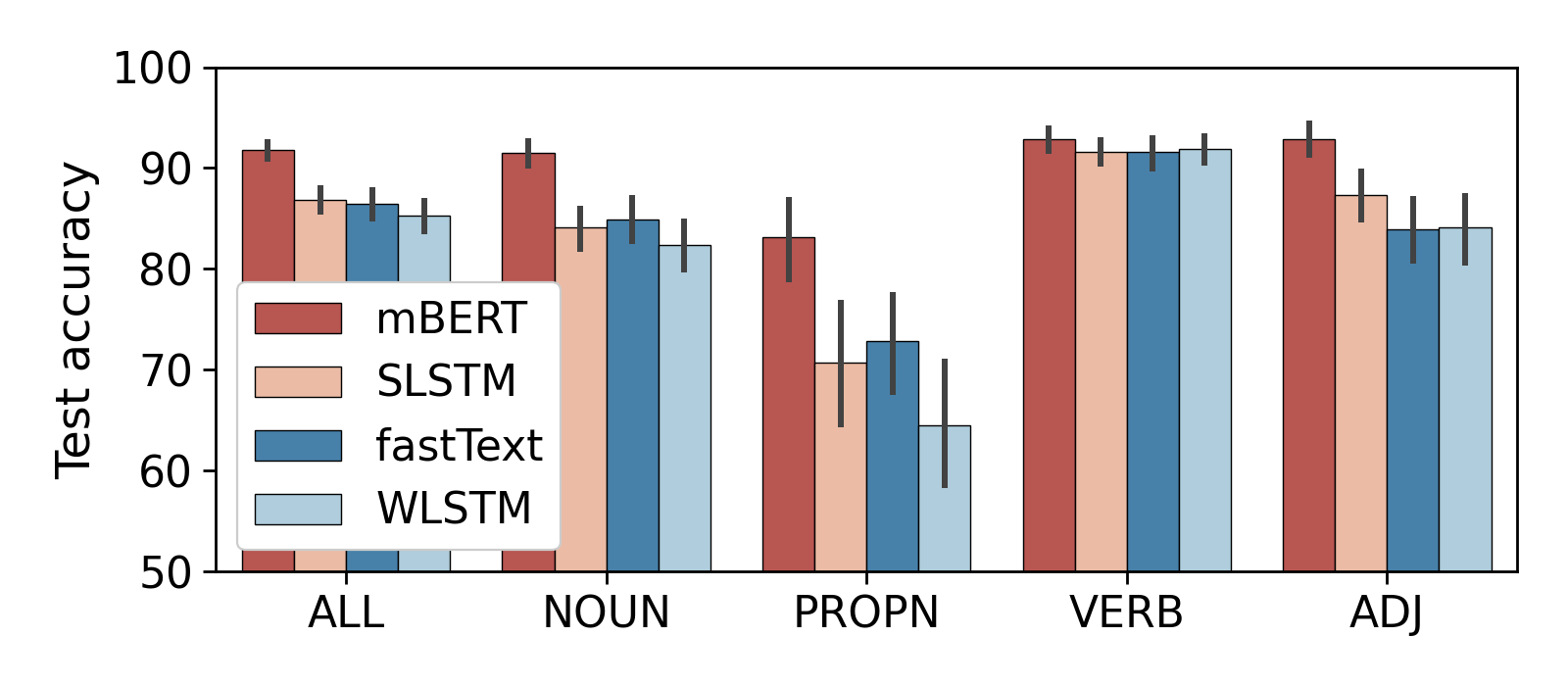
Verbal vs. nominal inflection
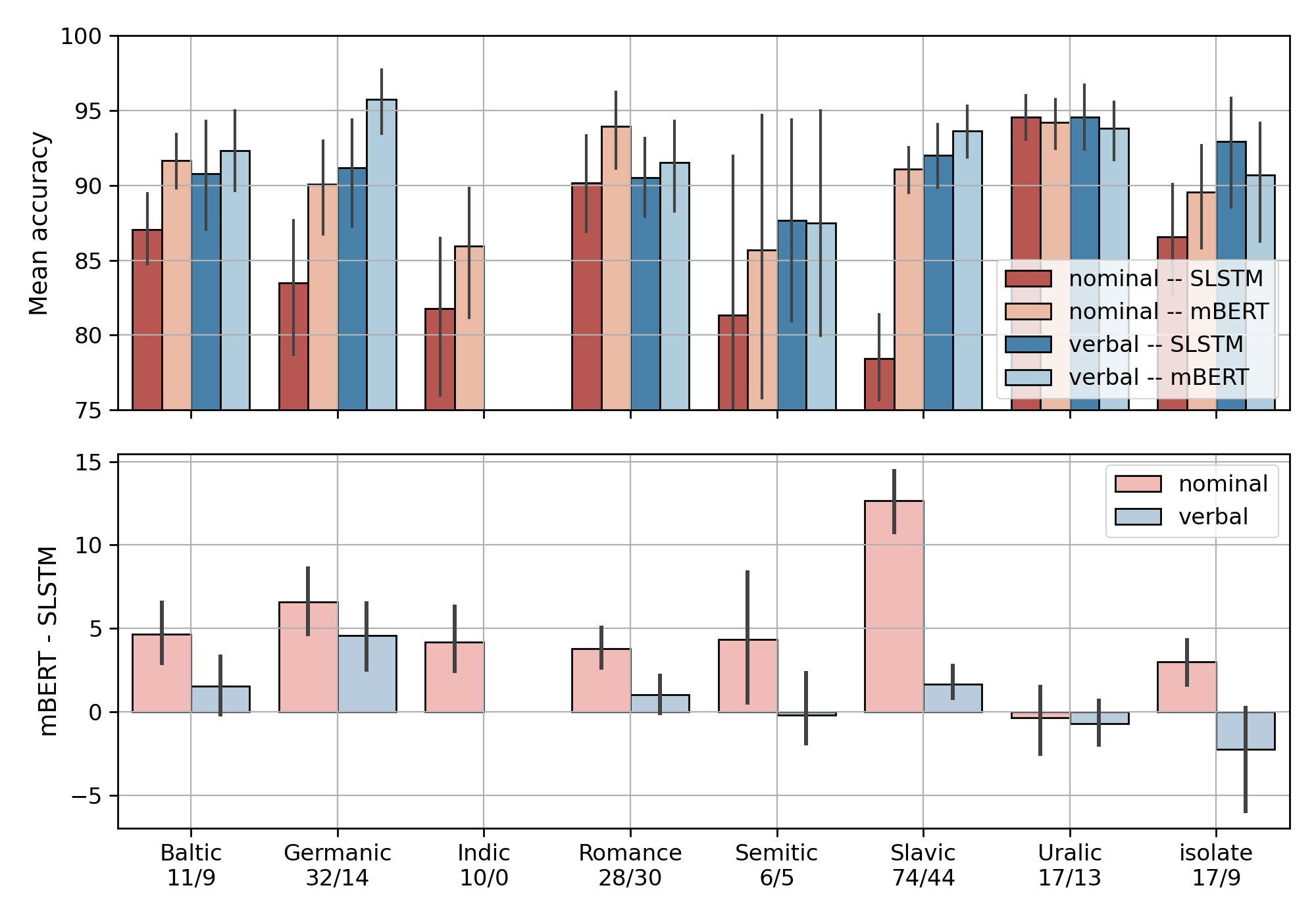
By language
- mBERT > SLSTM in more than half of the tasks in 28 out of 39 languages
- mBERT better at all tasks in Afrikaans, Dutch, Farsi, Hindi, Italian, Lithuanian, Serbian
- mBERT > SLSTM in less than half of the tasks in Albanian, Basque, Estonian, Finnish, Hebrew, Hungarian, Latin, Turkish, Urdu
Input perturbations
Shapley values
Perturbations

Perturbation effect
- Remove a source of information from the sentence
- Retrain the probe from scratch
- Quantify the information loss
- 0 if the perturbation doesn't affect the probing accuracy
- 100 if it breaks it completely
- negative if there is an improvement
Mean effects
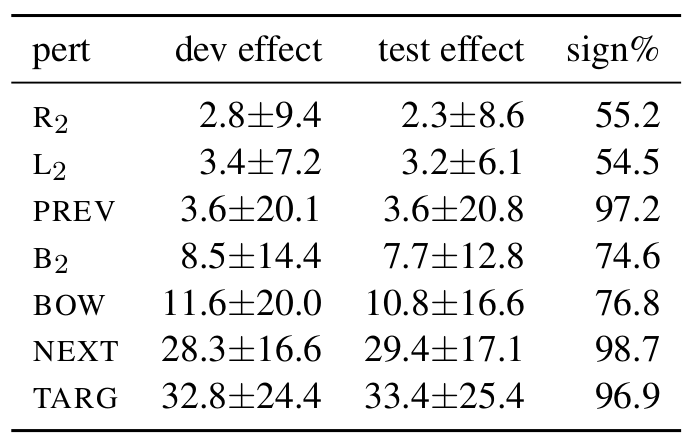
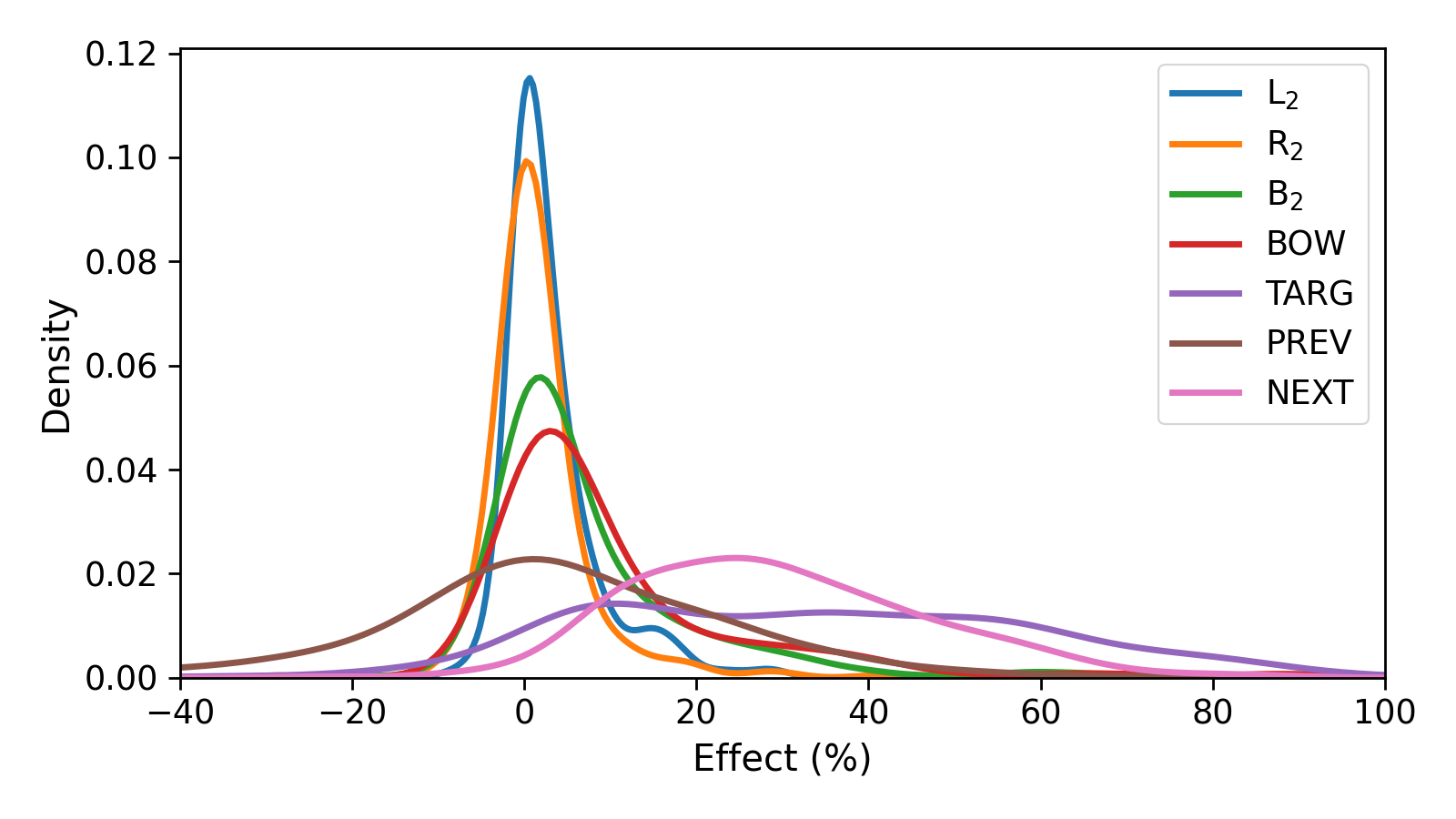
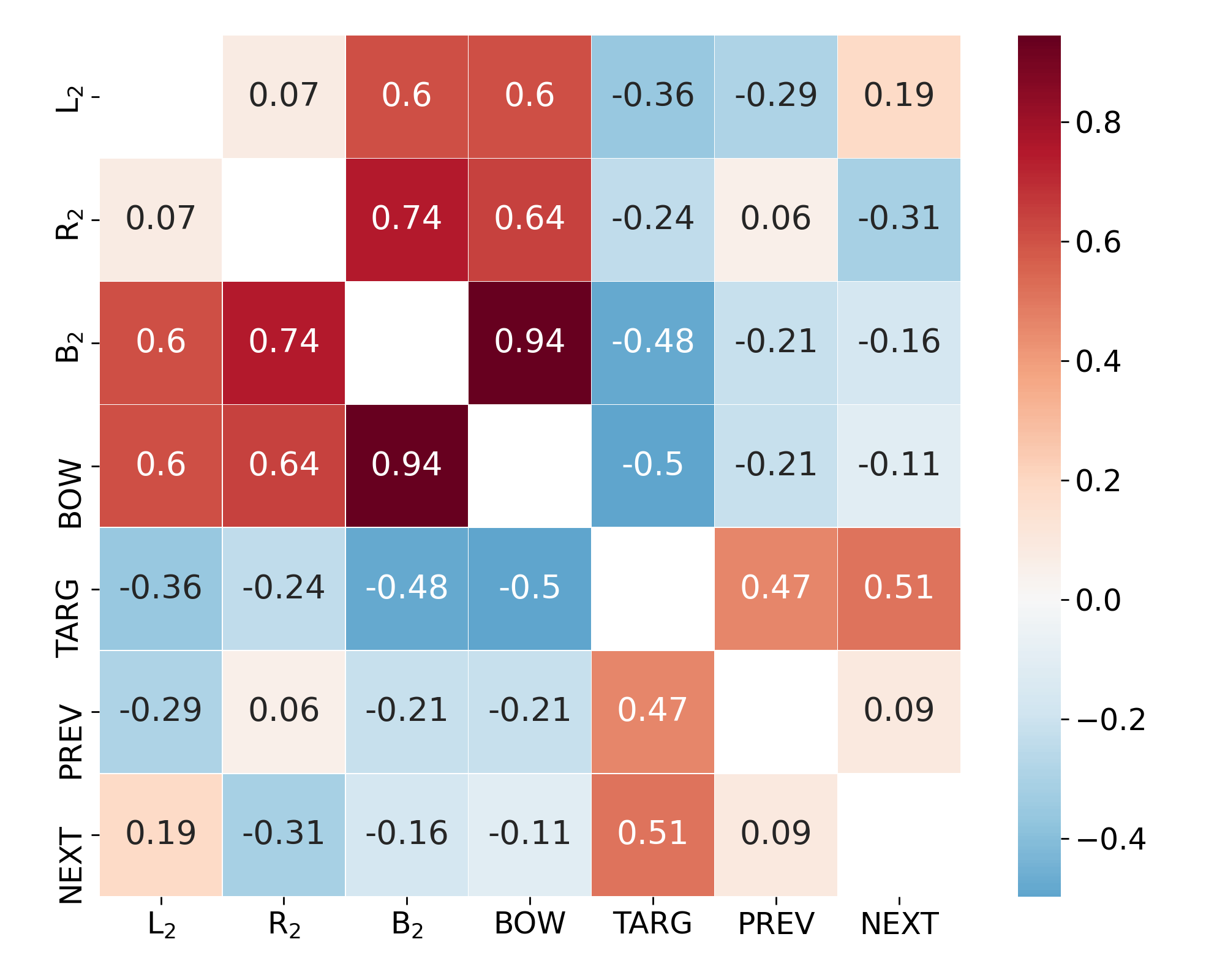
Relation between perturbations
Observation 1:
Linear regression with $\text{RMSE}=5.43$$ \text{BOW} \approx 1.22 \cdot B_2 + 1.42 $
Observation 2:
Left context is more important than right context- $ \text{Effect}(L_2) > \text{Effect}(R_2) $
- $\rho(\text{PREV}, \text{TARG}) > \rho(\text{NEXT}, \text{TARG})$
Shapley value
- Shapley, 1951
- Solution conecpt in cooperative game theory
- A coaliation of players cooperates and obtains certain overall gain
- Some players contribute more, some may contribute negatively
- The Shapley value is the individual contribution of each player
- 100: contributes all, 0: contributes nothing, negative: even worse
- Tokens are players
- Relative positions to the target token
- 0: target, -1: previous token, 1: next token
Shapley values 1.
- Target is the most important (59), context 41
- Left context contributes more than right context (24.1 vs. 16.9)
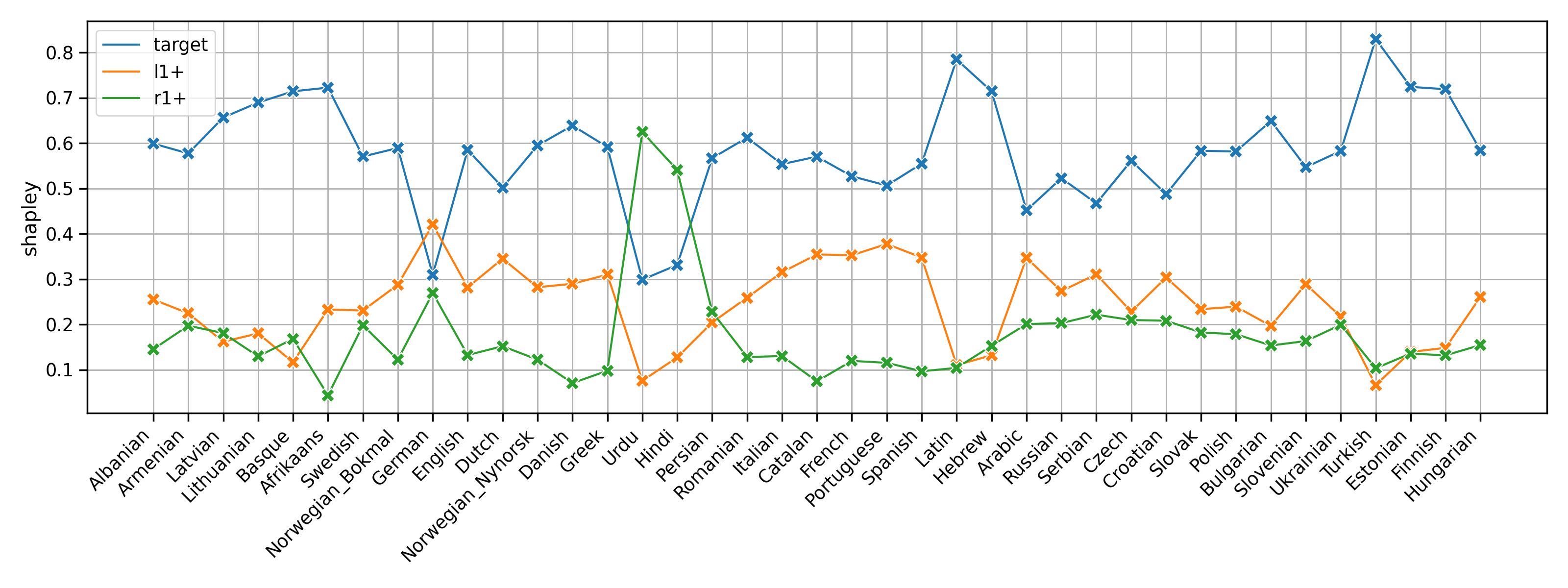
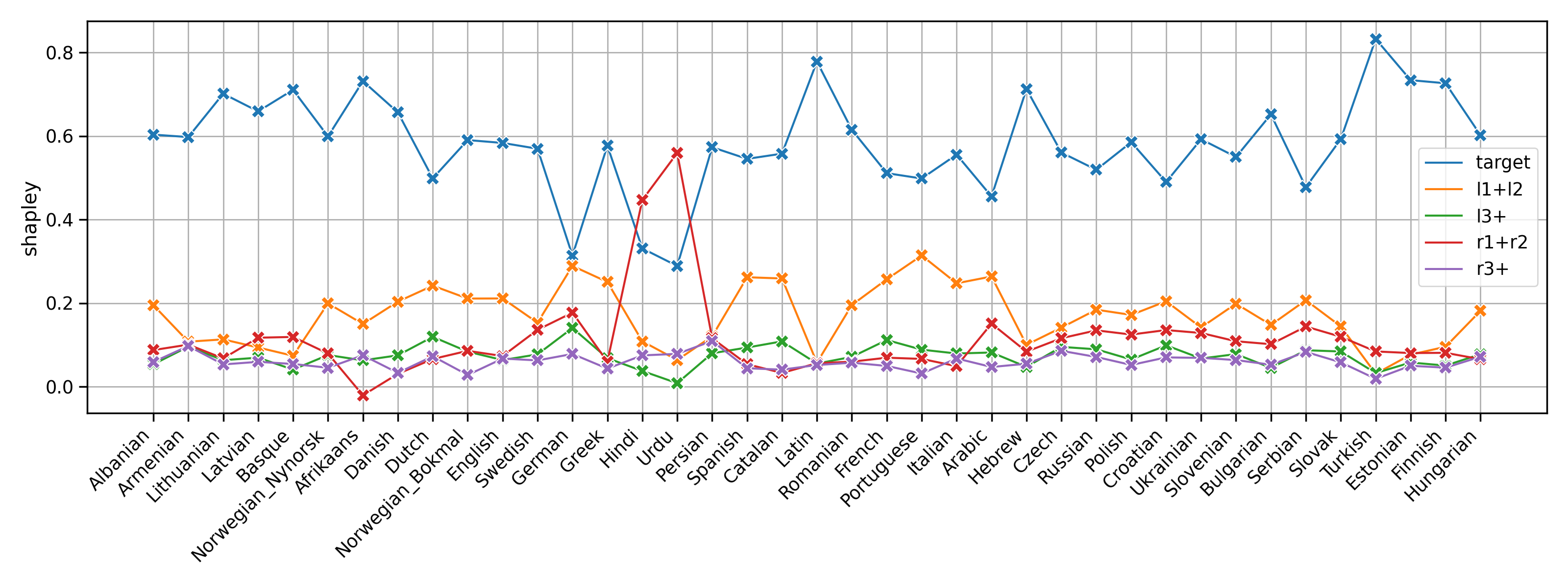
Shapley values 2.
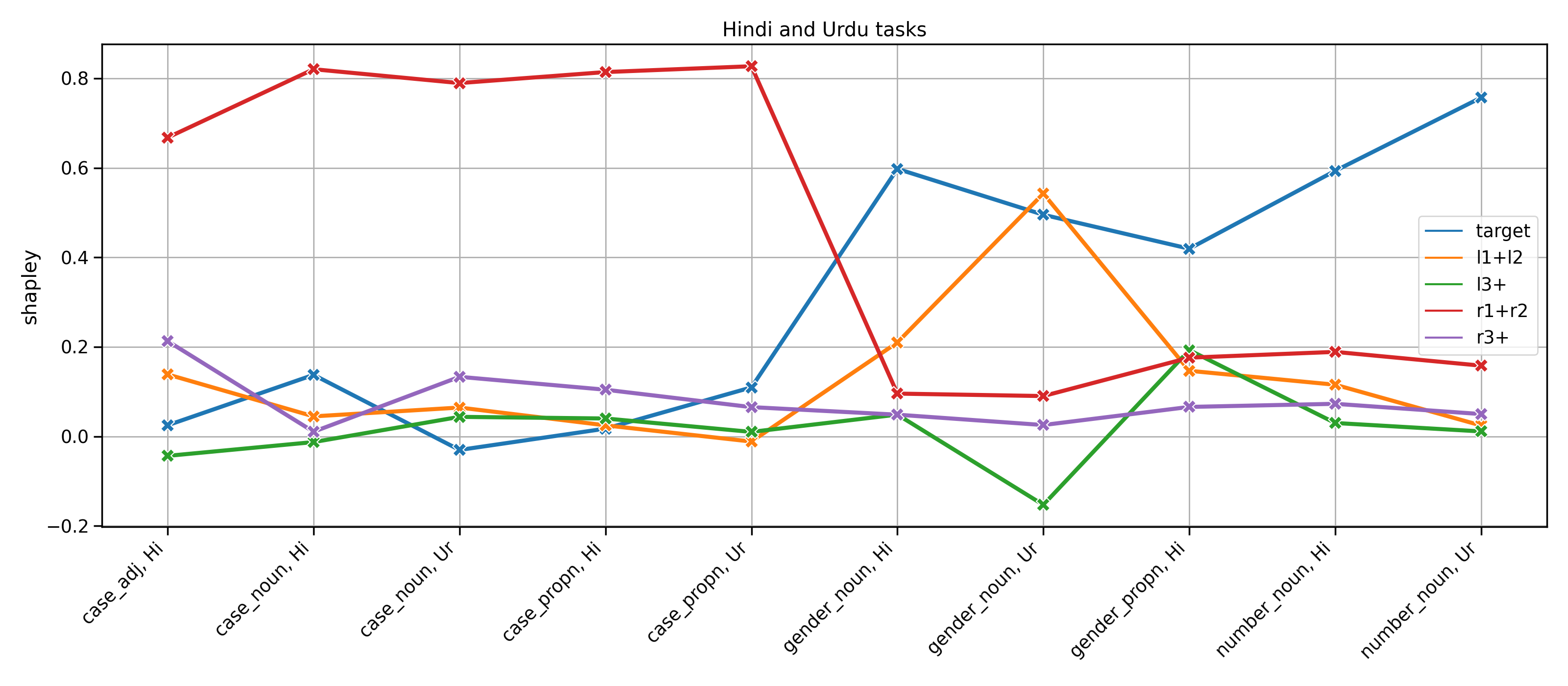
Shapley values 3. - Hindi and Urdu
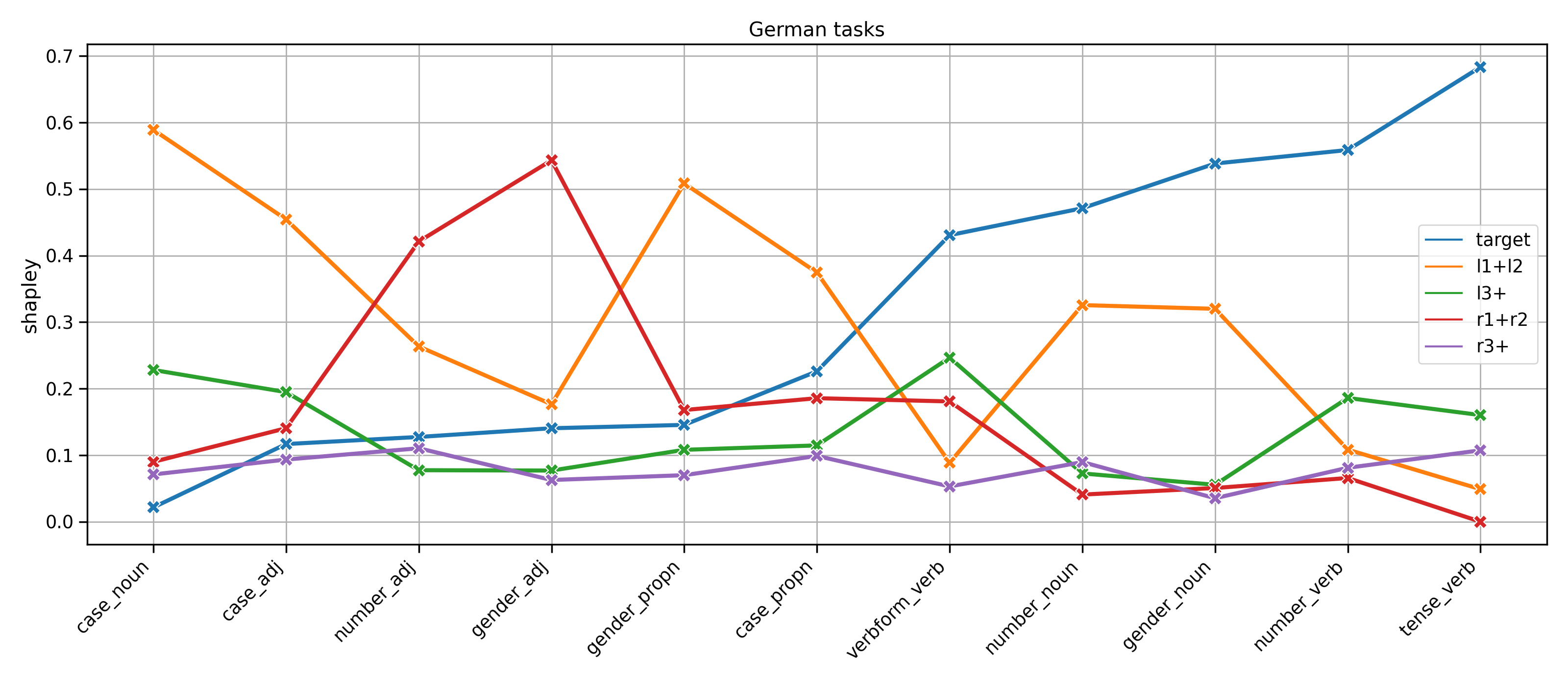
Shapley values 4. - German
Typology
Family
- aggregate over families
- red indicates that a family is affected above average
- blue means the family is affected less than the mean effect
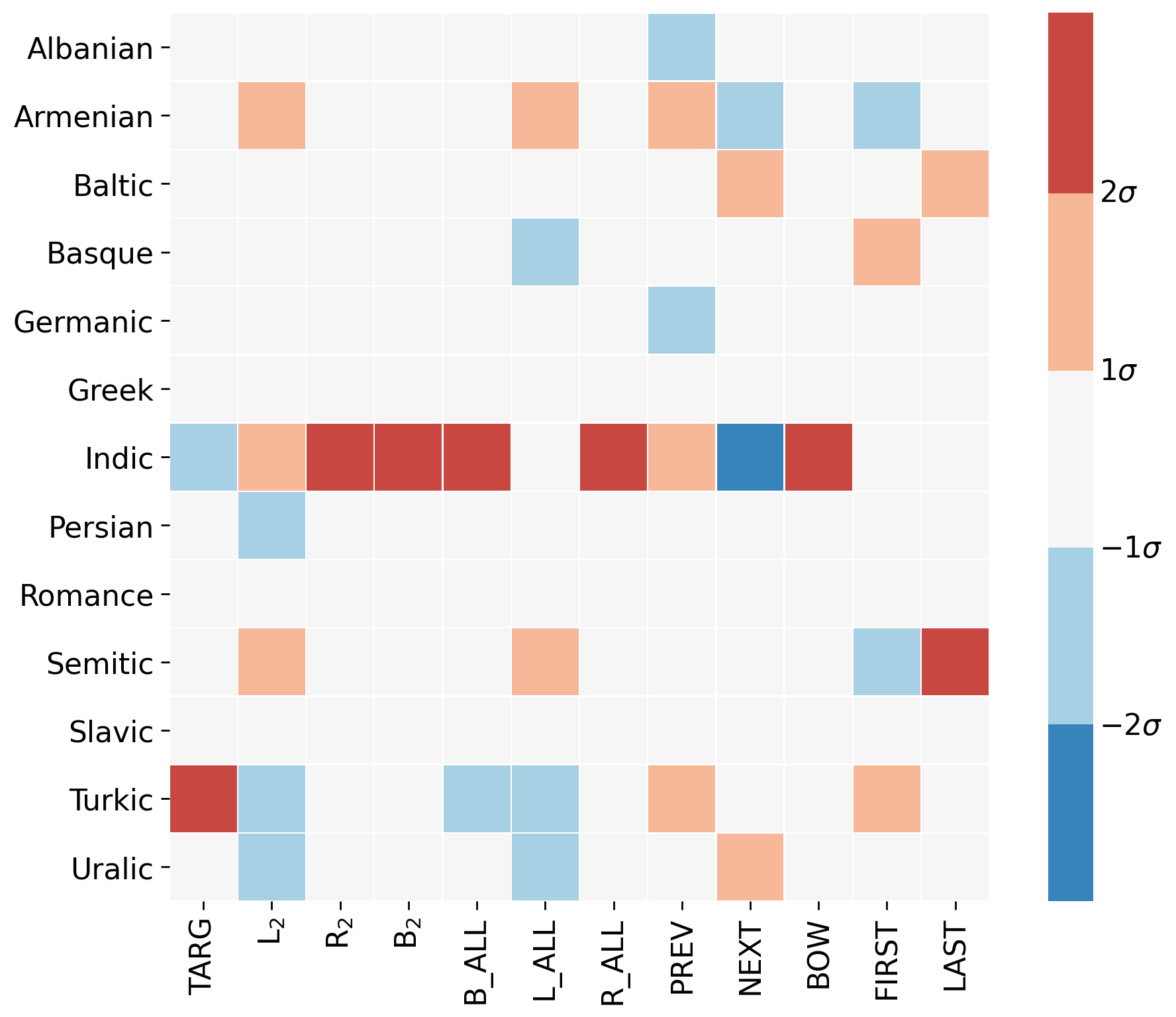
Clustering
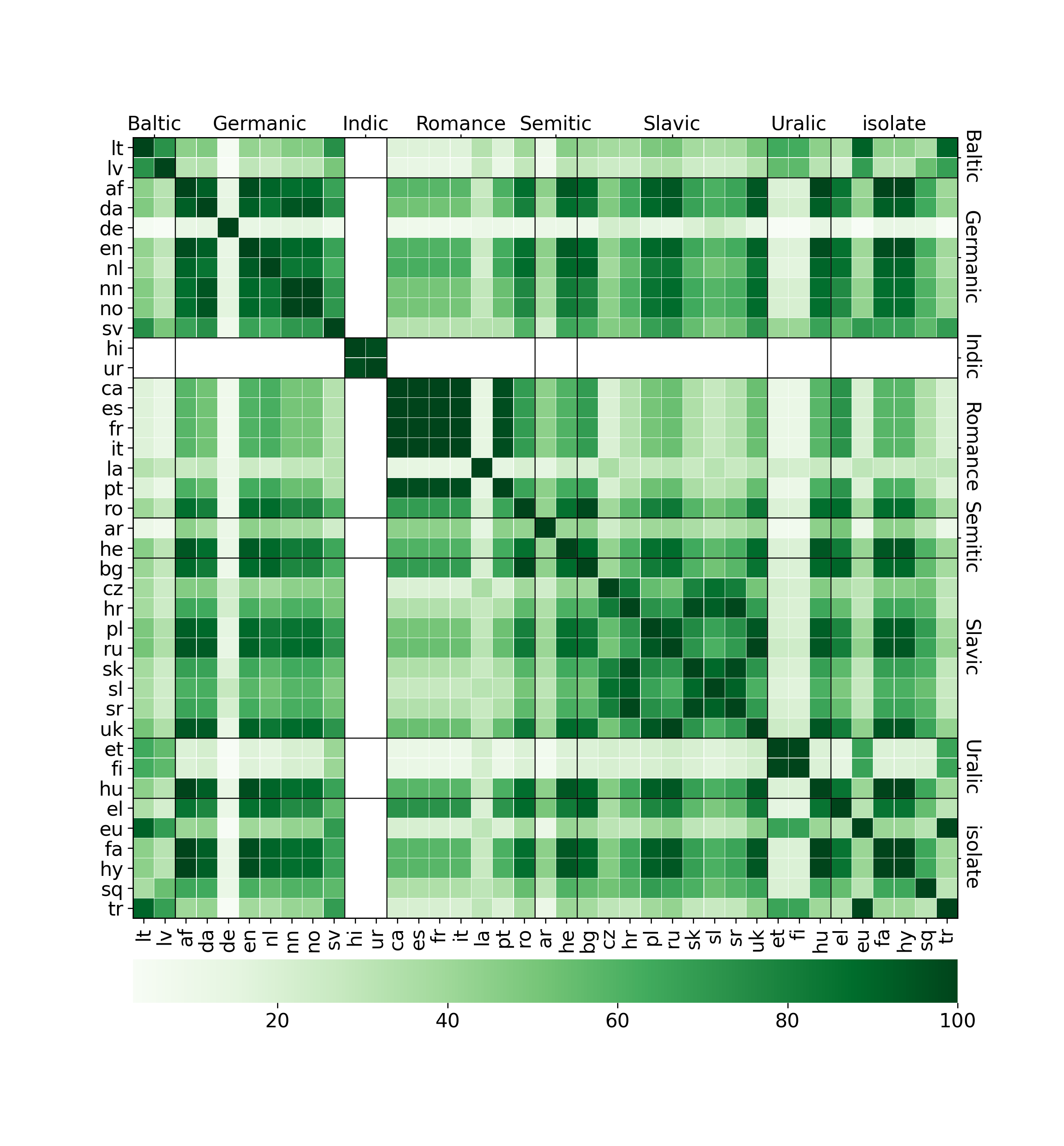
WALS
World Atlas of Languages
“a large database of structural (phonological, grammatical, lexical) properties of languages gathered from descriptive materials (such as reference grammars) by a team of 55 authors.”linguistic typology with 100+ fields for each language, many missing values
- we train logistic regression classifiers to predict a single WALS feature from perturbation effects alone
- 3-fold cross validation macro F-scores
- 15 most 'predictable' features
WALS
Paper and code
- About to submit a TACL paper
- Collaboration with Noah Smith, Roy Schwartz and András Kornai
- Dataset and data generator: github.com/juditacs/morphology-probes
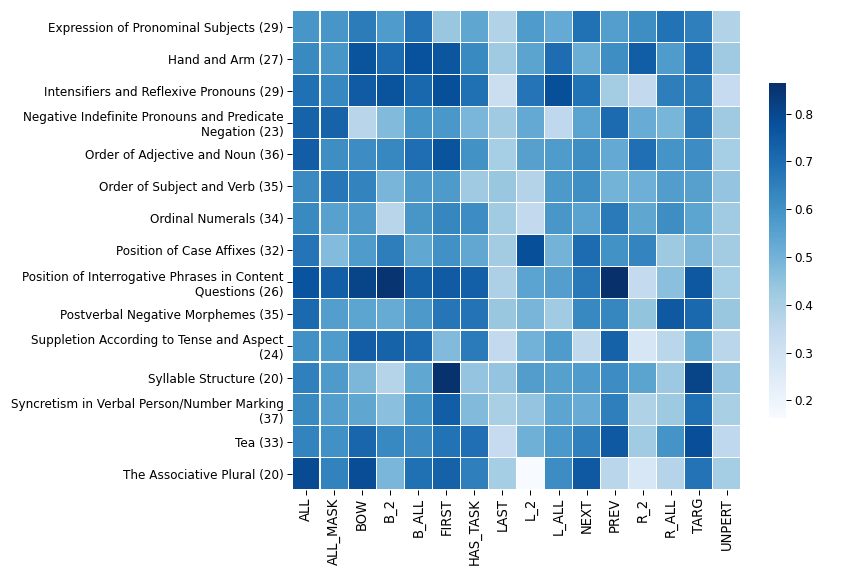
Choice of subword
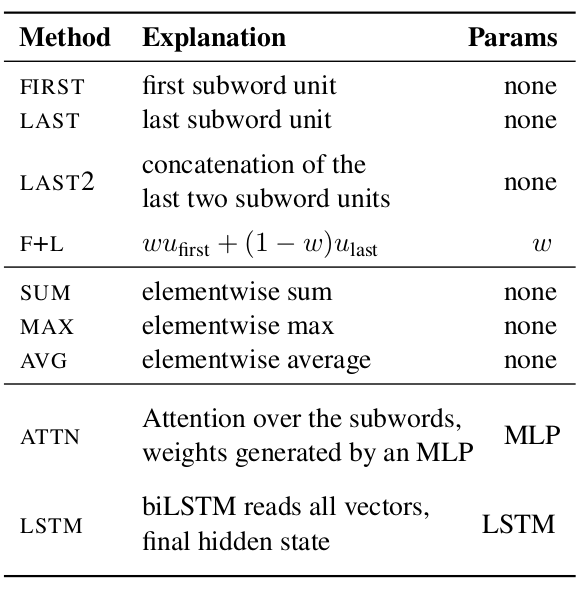
Subword pooling
- Token-level usage requires a way of aggrageting multiple subword representations
- Most popular: first or last subword, elementwise max/avg/sum
- Systematic comparison for morphology, POS and NER
- 9 typologically diverse languages
- mBERT and XLM-RoBERTa
First vs. last
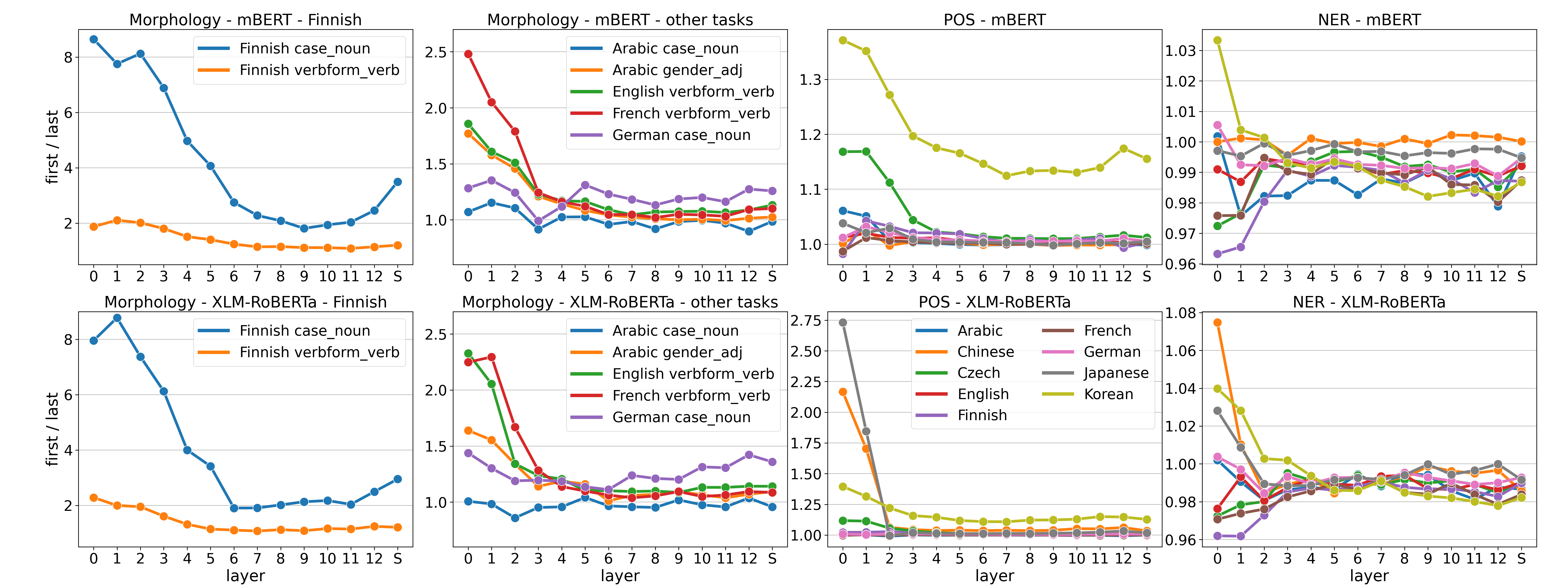
Morphology results
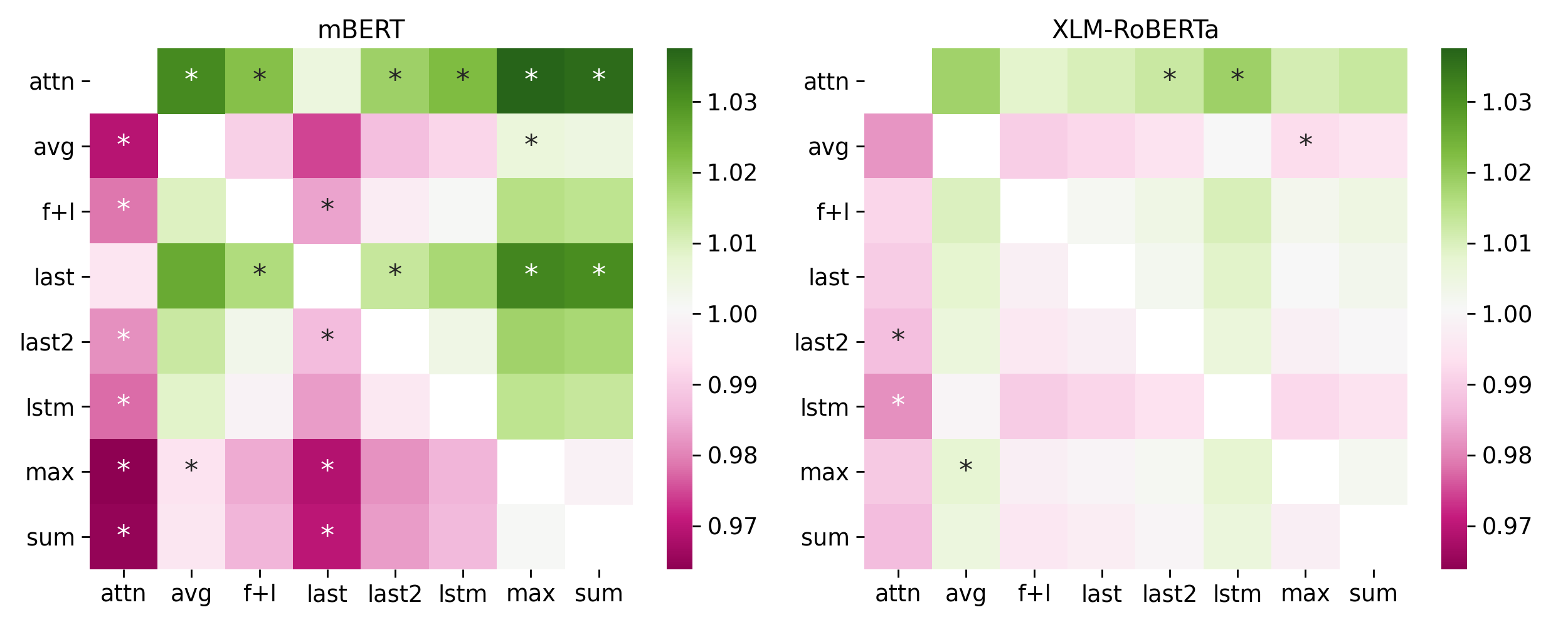 green: row pooling is better than column pooling
green: row pooling is better than column pooling
POS and NER
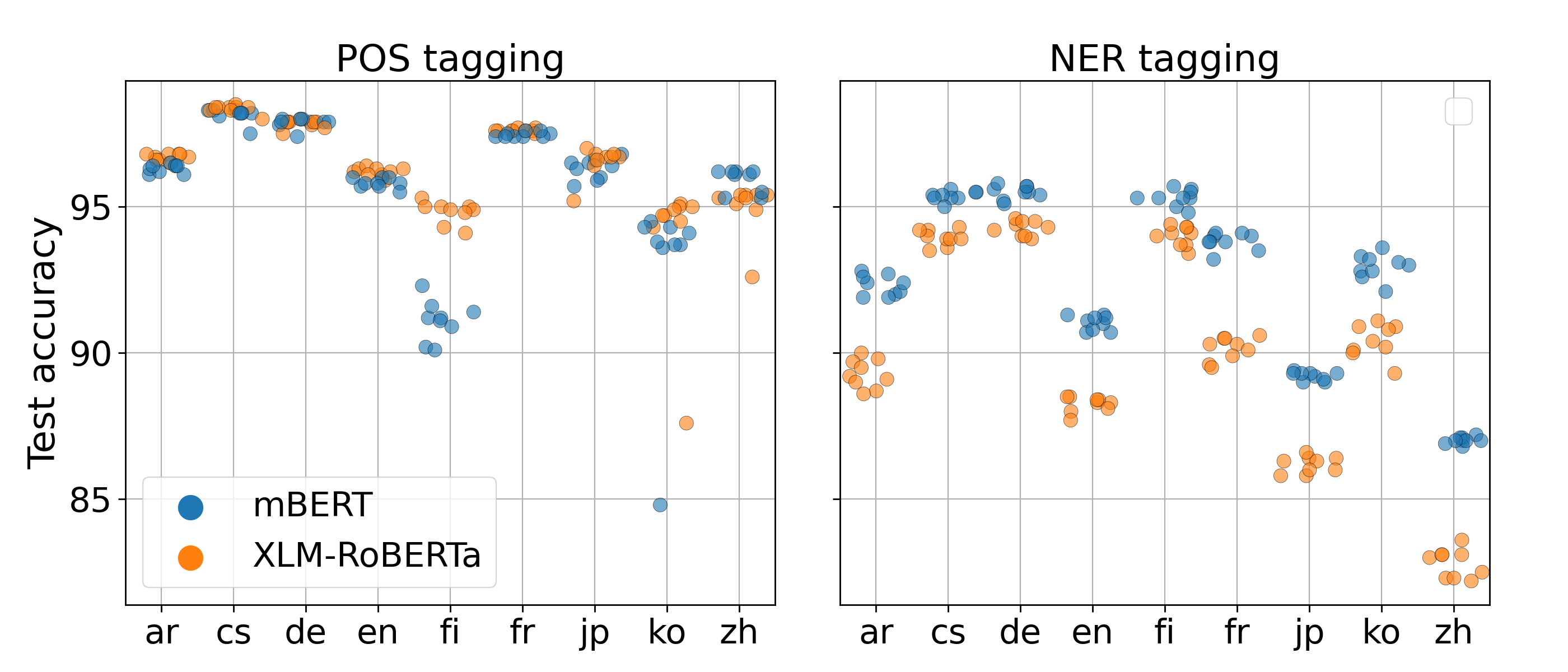 The differences are smaller and less often significant.
The differences are smaller and less often significant.
Paper and code
- Subword Pooling Makes a Difference, EACL2021
- Collaboration with Ákos Kádár and András Kornai
- https://arxiv.org/abs/2102.10864
- Code: https://github.com/juditacs/subword-choice
Evaluation for Hungarian
Models for Hungarian
| Languages | Training data | Details | |
|---|---|---|---|
| huBERT | Hungarian | Webcorpus 2.0 | BERT-base |
| HILBERT | Hungarian | MNSZ, JSI, NOL, OS, KM | BERT-large |
| mBERT | 100+ | Wikipedia | BERT-base |
| XLM-RoBERTa | 100 | CommonCrawl | BERT-base |
| XLM-MLM-100 | 100 | Larger version of XLM-RoBERTa | |
| distil-mBERT | 100+ | Distilled version of mBERT | |
Data
Morphology
| Morph tag | POS | # of values | Values |
|---|---|---|---|
| Case | NOUN | 18 | Abl, Acc, ..., Ter, Tra |
| Degree | ADJ | 3 | Cmp, Pos, Sup |
| Mood | VERB | 4 | Cnd, Imp, Ind, Pot |
| Number[psor] | NOUN | 2 | Sing, Plur |
| Number | ADJ | 2 | Sing, Plur |
| Number | NOUN | 2 | Sing, Plur |
| Number | VERB | 2 | Sing, Plur |
| Person[psor] | NOUN | 3 | 1, 2, 3 |
| Person | VERB | 3 | 1, 2, 3 |
| Tense | VERB | 2 | Pres, Past |
| VerbForm | VERB | 2 | Inf, Fin |
POS and NER
POS tagging
- Szeged UD: 910/441/449
- Webcorpus: 10000/2000/2000
NER tagging
- Szeged NER: 8172/503/900
Segmentation
- All models use subword segmentation
- Fixed vocabulary
- Multilingual models share the vocabulary over all languages
| huBERT | HILBERT | mBERT | XLM-RoBERTa | MLM-100 | |
|---|---|---|---|---|---|
| Vocab size | 32k | 64k | 120k | 250k | 200k |
| Word len in WP | 2.77 | 2.96 | 3.95 | 3.17 | 3.46 |
| Same as emtsv | 16% | 6.7% | 5% | 14% | 8% |
| Last WP same | 43% | 31% | 41% | 47% | 39% |
Segmentation
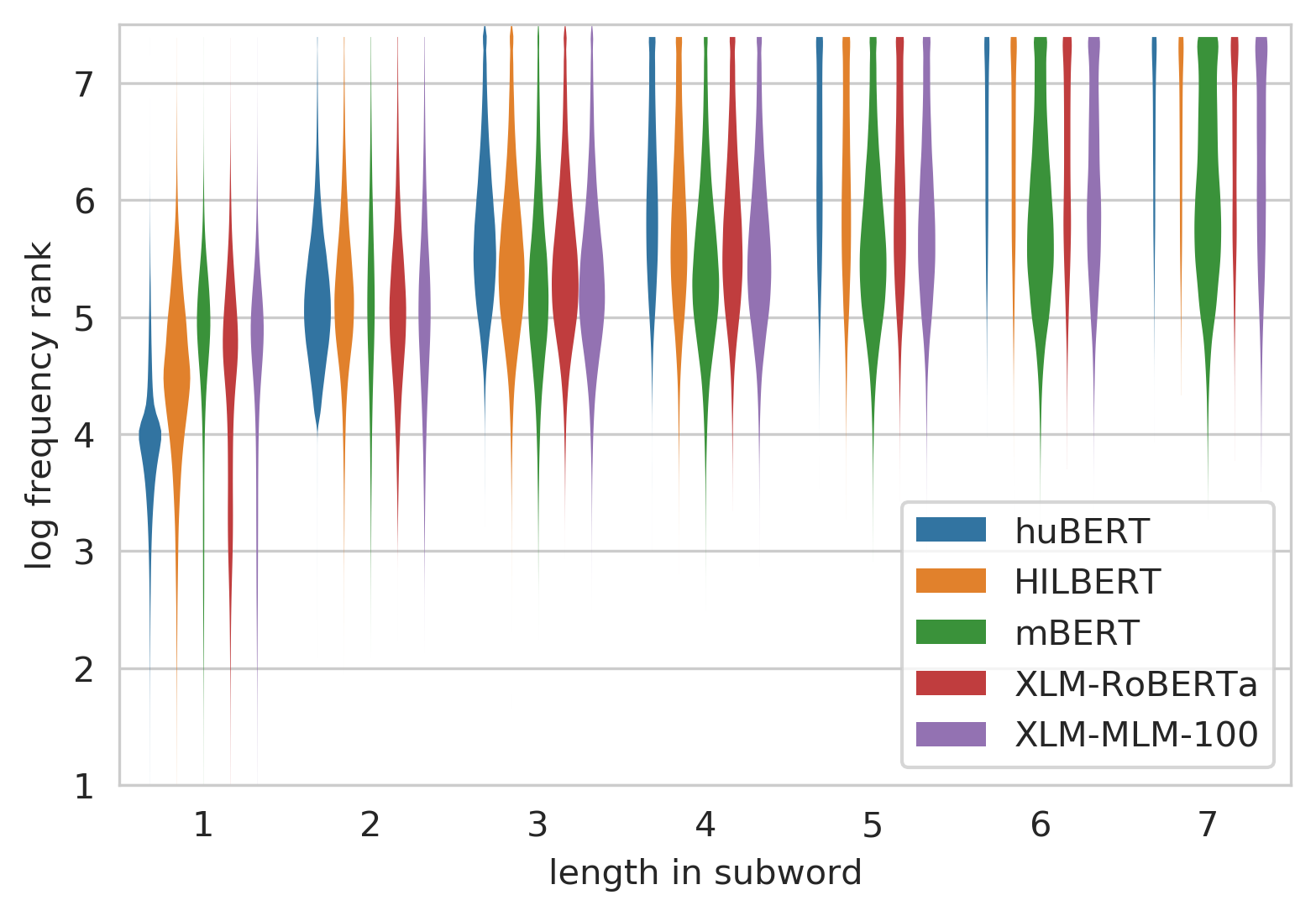
Results - morphology
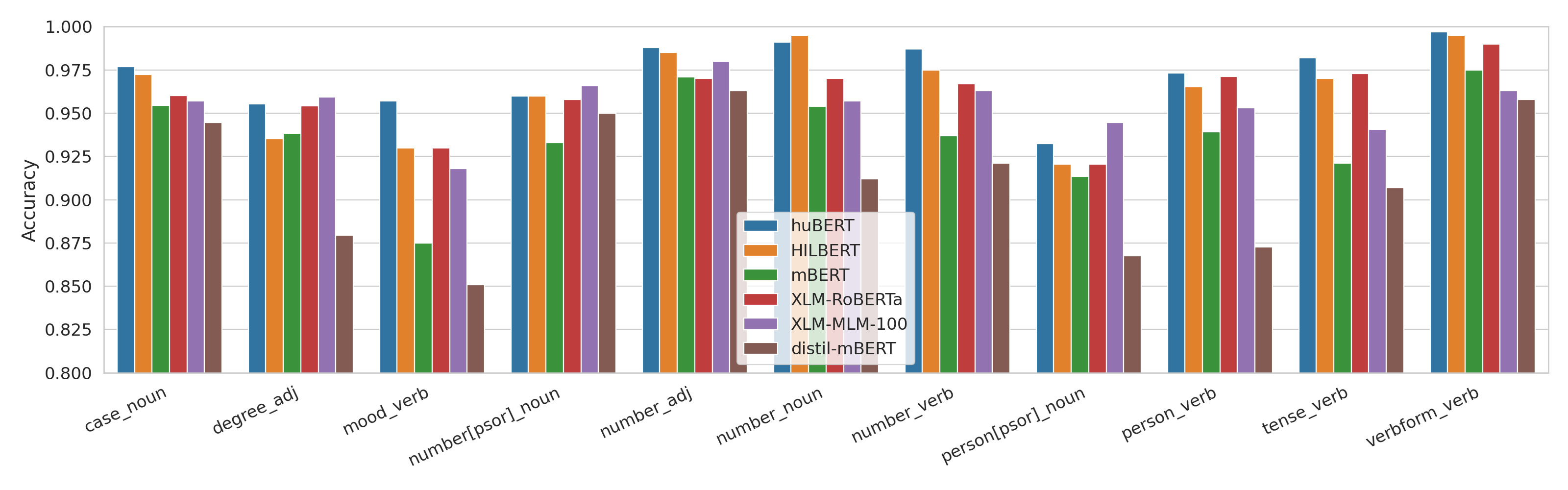
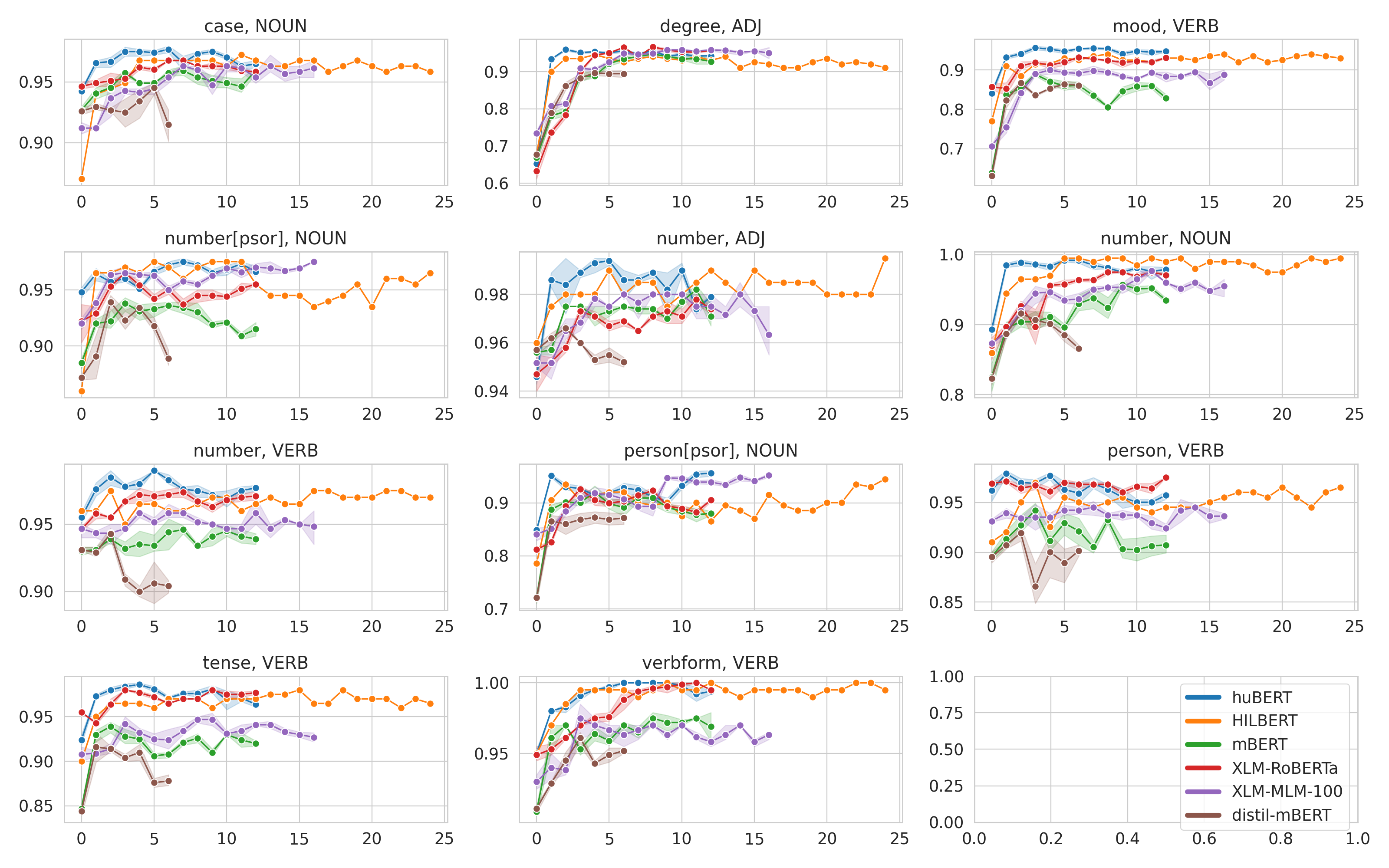
Results - POS
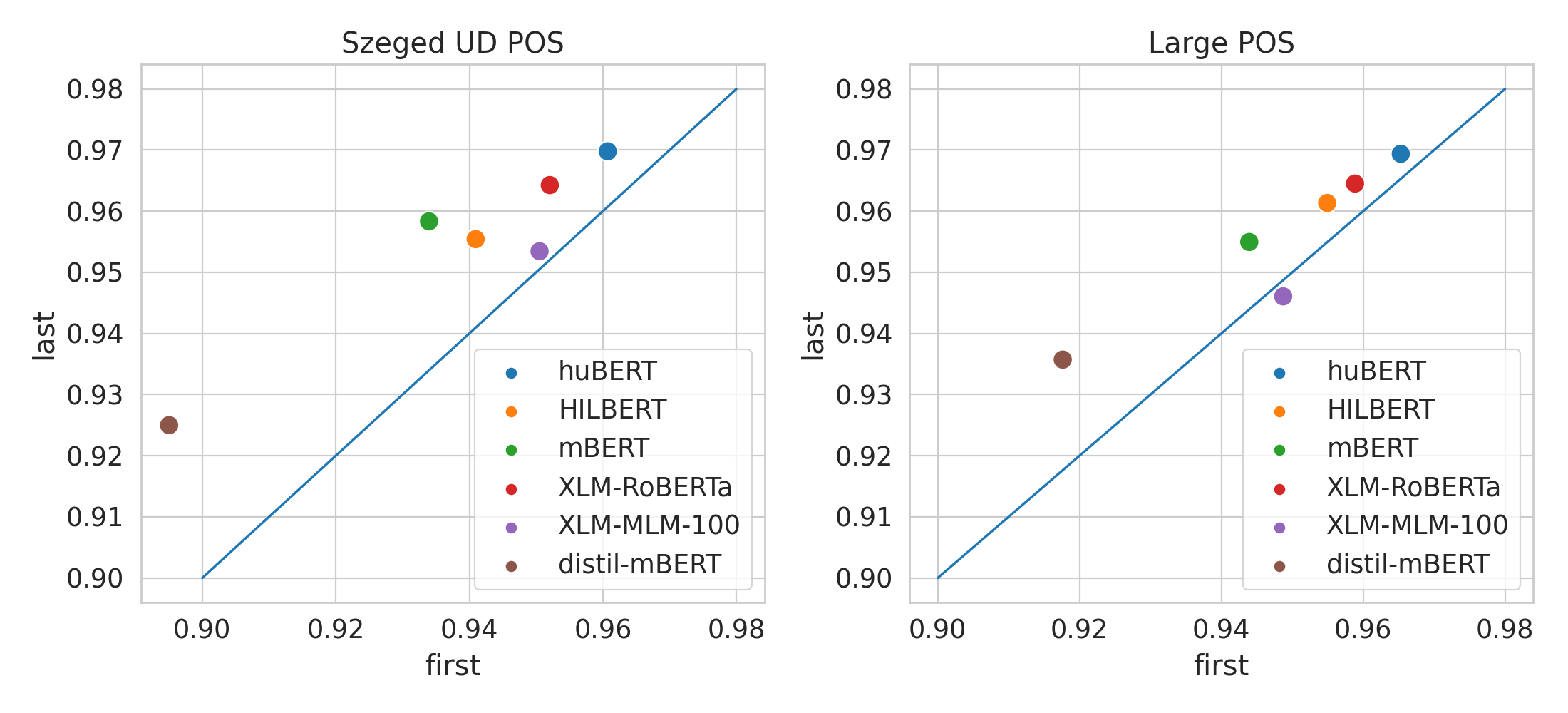
Results - POS
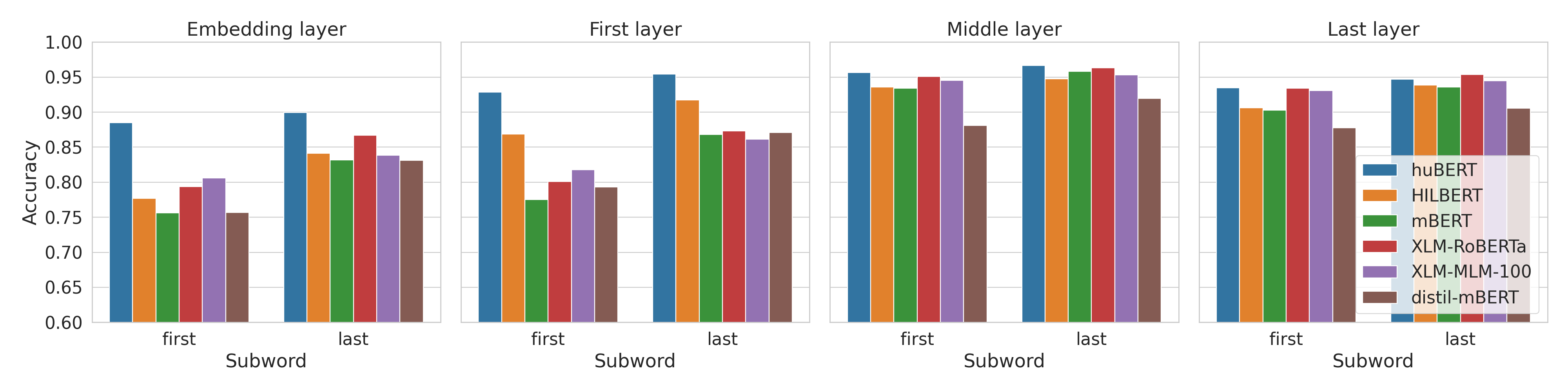
Results - NER
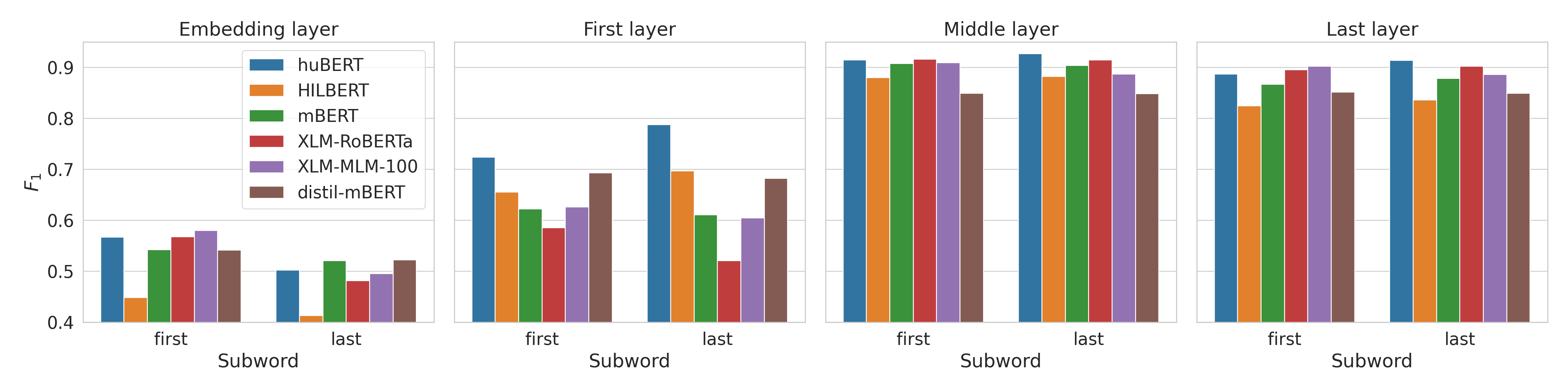
Paper and code
- Evaluating Contextualized Language Models for Hungarian, MSZNY21
- Collaboration with Dániel Lévai, Dávid Márk Nemeskey and András Kornai
- https://arxiv.org/abs/2102.10848
- Code: https://github.com/juditacs/hubert_eval